


So far on this blog, we’ve been looking at the publish/subscribe messaging pattern using MassTransit and RabbitMQ. So far, we’ve dealt with a single publisher and a single subscriber. We looked at how we can have those two roles live on separate servers. Finally, we looked at how to handle errors in the subscriber.
What happens, now, when your subscriber can’t process messages as fast as the messages are being published on the bus? This is a special situation, to be sure, but it certainly is possible in high message volume environments. It can be compounded if the messages themselves are fairly expensive to process.
Open the Flood Gates
Let’s take our simple publish/subscribe example and tweak it so we can have it dump a large number of messages onto the bus extremely quickly. Originally, the example prompted for a string and published that string as a single SomethingHappened message. Instead, let’s prompt for a number of messages that should be put onto the bus.
using Configuration;
using Contracts;
using System;
using System.Threading.Tasks;
namespace TestPublisher
{
class Program
{
static void Main(string[] args)
{
var bus = BusInitializer.CreateBus("TestPublisher", x => { });
string text = "";
while (text != "quit")
{
Console.Write("Enter number of messages to generate (quit to exit): ");
text = Console.ReadLine();
int numMessages = 0;
if (int.TryParse(text, out numMessages) && numMessages > 0)
{
Parallel.For(0, numMessages, i =>
{
var message = new SomethingHappenedMessage() { What = "message " + i.ToString(), When = DateTime.Now };
bus.Publish<SomethingHappened>(message, x => { x.SetDeliveryMode(MassTransit.DeliveryMode.Persistent); });
});
}
else if(text != "quit")
{
Console.WriteLine("\"" + text + "\" is not a number.");
}
}
bus.Dispose();
}
}
}
We’re using the System.Threading.Tasks.Parallel.For method to be able to simultaneously publish multiple messages onto the bus.
Now in our subscriber, let’s have it simulate 250 milliseconds of processing time with a call to System.Threading.Thread.Sleep. Also, because MassTransit will run 4 threads per CPU for our consumer and the messages will be flying in, we’ll condense our Console output to a single WriteLine call instead of multiple calls to Write so as to avoid the output from multiple messages getting jumbled together.
using Contracts;
using MassTransit;
using System;
using System.Threading;
namespace TestSubscriber
{
class SomethingHappenedConsumer : Consumes<SomethingHappened>.Context
{
public void Consume(IConsumeContext<SomethingHappened> message)
{
Console.WriteLine("TXT: " + message.Message.What +
" SENT: " + message.Message.When.ToString() +
" PROCESSED: " + DateTime.Now.ToString() +
" (" + System.Threading.Thread.CurrentThread.ManagedThreadId.ToString() + ")");
// Simulate processing time
Thread.Sleep(250);
}
}
}
Running the Test
The test code for this example can be found on github.
Make sure both TestPublisher and TestSubscriber are set up as startup projects and run the project in Visual Studio. Try publishing 1,000 messages:

As you could probably see, the prompt on the publisher returned well before the subscriber finished processing the messages. This means we were able to publish messages to the bus faster that we could process them. This could be a problem if you don’t expect any “lulls” in publishing which would allow the subscriber to catch up.
We can further illustrate the backlog by looking at the graph for the MtPubSubExample_TestSubscriber queue in the RabbitMQ management interface (found at http://localhost:15672/ – see this post for details). You have to have the interface up and be watching the graph while your publisher/subscriber test is actually running:

Here you can see that the publisher hit a peak of 200 messages per second, while the subscriber sustained a steady rate of about 40 messages per second.
With a spike and then nothing for a time, perhaps slow and steady wins the race for our subscriber. Try 10,000 messages and watch the RabbitMQ graphs:

This more dramatically illustrates the problem. The number of queued messages (top graph) is continuing to go up with no relief in sight. And the bottom graph shows we’re publishing messages at a rate of 259 per second, but we only process them at a rate of around 40 per second. Again, since the publish storm eventually passes, the subscriber does eventually catch up.
Let’s look at a couple ways we can increase the throughput of our subscriber.
Option 1: Increase the Prefetch Count
If you do the math on the rate of 40 messages per second that we observe, you will arrive at what appears to be 10 simultaneous threads processing messages (each message takes a quarter of a second). However, the default number of threads that MassTransit can use for consumers is actually the number of processors in your machine multiplied by 4. So, on my 8 core machine, that would be 32 threads. Why are we only observing 10?
The reason is due to the number of messages the RabbitMQ transport will “prefetch” from the queue. The default for this is 10, so we can only process 10 messages simultaneously. To increase this, you include a “prefetch=X” parameter in the query string of the queue URL. For example:
x.UseRabbitMq();
x.ReceiveFrom("rabbitmq://localhost/MtPubSubExample_" + queueName + "?prefetch=32");
Now that this is set to 32 to match the maximum thread of 32, we should observe a 128 message per second processing rate.
Option 2: Increase the Thread Count
We can also tell MassTransit to allow more threads to be used to consume messages. You put a call to SetConcurrentConsumerLimit in your bus initialization code. Below we bump the thread count to 64 (doubling the number of threads):
using Configuration;
using MassTransit;
using System;
namespace TestSubscriber
{
class Program
{
static void Main(string[] args)
{
var bus = BusInitializer.CreateBus("TestSubscriber", x =>
{
x.SetConcurrentConsumerLimit(64);
x.Subscribe(subs =>
{
subs.Consumer<SomethingHappenedConsumer>().Permanent();
});
});
Console.ReadKey();
bus.Dispose();
}
}
}
Don’t forget to also increase your prefetch setting (see option 1 above) to match. Now we’re processing 256 messages per second! That’s pretty close to our 259 per second we observed being published onto the bus.
However, at some point, your machine is going to run out of processing power. Perhaps it already has. We’re just sleeping the thread here for 250ms, so the ceiling is pretty high on how many threads we could run, but if there was real processing happening, we might be maxing out the CPU on the machine. As any good architect knows, don’t scale up, scale out!
Option 3: Run More Subscribers
Try dumping another 10,000 messages onto the bus. While you’ve got one subscriber running, you can simply execute another instance of the TestSubscriber executable and it will start processing messages too, effectively doubling your processing rate!
Having multiple subscribers connected to the same RabbitMQ queue is what’s called the “competing consumer” pattern. RabbitMQ will make sure each consumer gets unique messages in essentially a round-robin fashion.
Again, however, if we’re already maxing out the CPU on the subscriber machine, what we really need is to run another subscriber on another machine with its own available resources. If we use our current example code, however, we will get duplicate messages because each machine is connecting to localhost for its RabbitMQ instance. (Don’t forget to make sure all the RabbitMQ instances are in a cluster.) Since each instance will have its own queue, then MassTransit will treat each queue as a unique consumer as opposed to competing consumers. Each queue will get a copy of the same message routed to it. Remember this diagram from our clustering article illustrating how each machine has its own RabbitMQ instance:
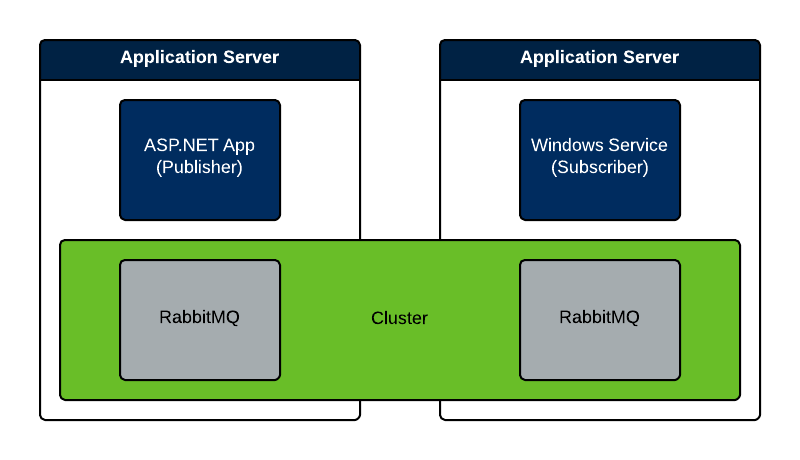
Clearly, this is not what we want. In order to be competing consumers, the two subscriber processes must be connected to the same RabbitMQ instance and queue. What we need is an architecture more like the following:

Obviously, this makes the RabbitMQ server a single point of failure and a dependency for the two subscriber machines. If high availability is a requirement, then you would need to look into some type of virtual IP address based clustering (like keepalived on Linux or NLB on Windows). You will also need to implement highly available queues in RabbitMQ so that the queues are replicated across your multiple instances.
Implementing the Centralized RabbitMQ Server
Obviously, the first step is to install RabbitMQ on a new server. We’ll call this machine “submaster” (for subscription master). Instructions for installing RabbitMQ can be found in this blog post. Then, join the RabbitMQ instance on submaster to a cluster with the RabbitMQ instance on your publisher machine. Instructions for creating a RabbitMQ cluster can be found in this blog post. We should have these nodes in our RabbitMQ cluster:

In order to connect to a remote RabbitMQ instance, we need to do some security housekeeping. First, we need to modify the Windows Firewall on the submaster machine to allow in the default RabbitMQ port of 5672. Next, we need to create a new user in RabbitMQ that the subscriber can use to login. We’ll call it “testsubscriber” and give it a password of “test”. On the Admin tab of the RabbitMQ management interface, you can begin adding a new user:

Type in the username, password, administrator tag, and click Add user. Initially, the user won’t have any permissions:

Click on the testsubscriber user and then click “Set permission” as seen here:

Now we need to modify our Configuration.BusInitializer class to be able to connect to a specific machine name instead of hard-coding localhost as well as utilize our username and password. We’ll have it read these items from our App.config. Remember, our publisher can still use localhost (which doesn’t require username/password), but our subscriber needs to connect to the submaster machine with some credentials.
First, add a reference to System.Configuration to the Configuration project. Then modify the BusInitializer class to allow reading the machine name, username, and password from configuration:
using MassTransit;
using MassTransit.BusConfigurators;
using MassTransit.Log4NetIntegration.Logging;
using System;
using System.Configuration;
namespace Configuration
{
public class BusInitializer
{
public static IServiceBus CreateBus(string queueName, Action<ServiceBusConfigurator> moreInitialization)
{
Log4NetLogger.Use();
var bus = ServiceBusFactory.New(x =>
{
var serverName = GetConfigValue("rabbitmq-server-name", "localhost");
var userName = GetConfigValue("rabbitmq-username", "");
var password = GetConfigValue("rabbitmq-password", "");
var queueUri = "rabbitmq://" + serverName + "/MtPubSubExample_" + queueName + "?prefetch=64";
if (userName != "")
{
x.UseRabbitMq(r =>
{
r.ConfigureHost(new Uri(queueUri), h =>
{
h.SetUsername(userName);
h.SetPassword(password);
});
});
}
else
x.UseRabbitMq();
x.ReceiveFrom(queueUri);
moreInitialization(x);
});
return bus;
}
private static string GetConfigValue(string key, string defaultValue)
{
string value = ConfigurationManager.AppSettings[key];
return string.IsNullOrEmpty(value) ? defaultValue : value;
}
}
}
Since we’re only going to deviate from the default of localhost on our subscriber, open the TestSubscriber project and add the following lines into the App.config:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<appSettings>
<add key="rabbitmq-server-name" value="submaster" />
<add key="rabbitmq-username" value="testsubscriber" />
<add key="rabbitmq-password" value="test" />
</appSettings>
</configuration>
Running the Test
On my dev machine, I fired up one instance of TestSubscriber with the above configuration. Then, on the publisher machine, I started up both TestPublisher and TestSubscriber. Here’s it running after pushing 100,000 messages onto the bus:

Lots of blinking lights. The more interesting thing is to observe the messages processed per second in RabbitMQ:

Wrap Up
So now you can see how it would be possible to scale out your message processing. Perhaps in a future post, we’ll take a look at leveraging the cloud. It should be possible to monitor the number of messages in your queue and spin up new cloud workers to pick up the slack and then shut them down when the queue quiets back down. Until then…
Great tutorial David, it helped me a lot.
Though i have one question about Runtime Services.
My Runtime Services are also running on “submaster”, how can i use credientials for this server while using Subscription Service from Publisher.
When i call UseSubscriptionService, how can i authenticate?
Runtime Services are only necessary for MSMQ. I do not have any experience using MassTransit with MSMQ. When using RabbitMQ, there’s no need for the Runtime Services because RabbitMQ handles all of the subscription persistence for you. Also, FYI, MSMQ support is being dropped in MassTransit 3.
Thanks David. Actually i need to check nodes health and show to client. For that i was using Health Services, and Health Services can only be used with Runtime Services (Subscription Services).
Any idea how can i store nodes health in database?
Again, I haven’t used any of MT’s runtime services, including the health service. Personally, I use Nagios for infrastructure monitoring (http://www.nagios.org/). Perhaps more important than the health of an individual node is the health of your queues. Take a look at http://looselycoupledlabs.com/2014/08/monitoring-rabbitmq/ for how to keep an eye on your queues. For services, I usually setup in Nagios what are called “passive checks”… Nagios doesn’t actively ping the services, but expects the services to “report in” on a set interval.
You could roll your own simple variation of this. Have each note report in to a database to say “I’m still alive as of this timestamp” and then write a centralized script or program that monitors that database for stale report times (the assumption being if a report time is over X minutes old, then the node is having problems).
Good luck!
Thanks David, actually i have setup the health services with help of your post “RabbirMQ Monitoring”.
I don’t thing that you have to connect to the same RabbitMQ instance when using competing consumers. The two subscriber processes can be connected to different RabbitMQ instances in the cluster using the same queue name.
I’m really confused by this line:
Assuming we have two app servers and one RMQ server, and both competing consumers are connecting to the same queue name on the single RMQ server, why do we need a cluster?